속성 조인, 공간 조인, 중첩 분석 등을 통해 데이터를 결합하면 더 많은 정보를 얻을 수 있을까요?
ArcGIS에서 데이터의 관계성을 사용하여 분석하는 기능은 서로 다른 소스의 데이터 셋을 동시에 활용하여 새로운 정보를 제공합니다. 데이터 셋은 파일 간 공통 속성 정보를 통해 조인이 가능하고, 위치 정보를 사용하여 ArcGIS에서 공간 데이터에 쉽게 조인할 수 있습니다. 또한, 점, 선, 면 등 다양한 피처 유형으로 저장된 정보를 결합할 수 있으며, 여러 래스터 데이터 셋의 데이터를 단일 래스터로 결합할 수 있습니다.
대상 위치의 데이터의 관계성을 결정한다면, 다음과 같은 유형의 질문에 답변할 수 있습니다.
- 해당 특성은 어디에서 발견됩니까?
- 이 지역에 몇 명이 거주합니까?
- 어떤 건물에 영향을 미칠 것입니까?
- 두 데이터가 같은 영역에서 발생합니까?
- 시간이 흐르면서 영향을 받는 지역이 바뀌었습니까?
- 얼마나 많은 사람이 영향을 받습니까?
이번 실습에는 데이터 관계성을 이용하여 속성 조인, 유사성 분석을 통한 래스터 데이터를 생성하려 합니다 🙂 LA에서는 노숙자 문제 해결을 위한 우선 순위를 선정하기 위해 심각성을 조사하려고 합니다. 분석에 가장 적절한 데이터를 이용하여 취약 지수를 산출하는 작업을 시작해보아요!
[Training : Combating Homeless in LA County]
☞ 데이터 불러오기
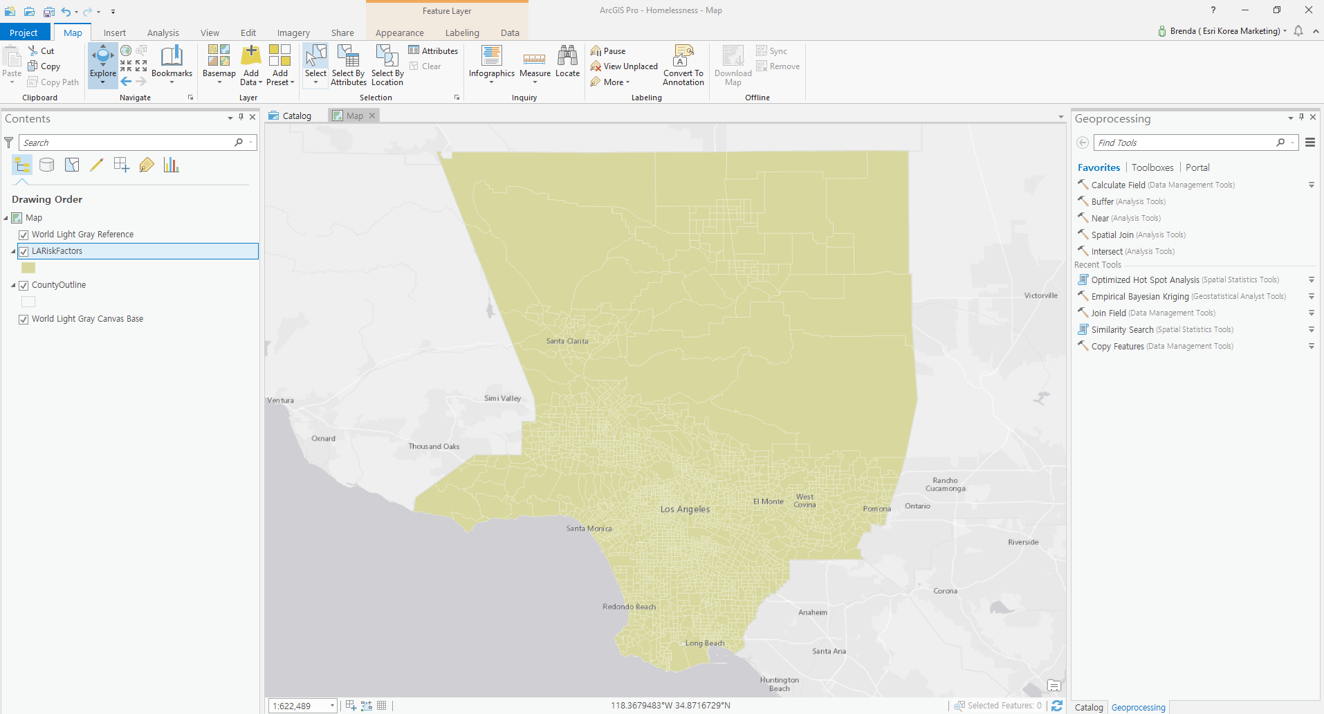
- ‘LARiskFactor’ 레이어의 속성 테이블을 열면 노숙자 발생 위험 요소를 나타내는 변수를 아래와 같이 확인할 수 있습니다.
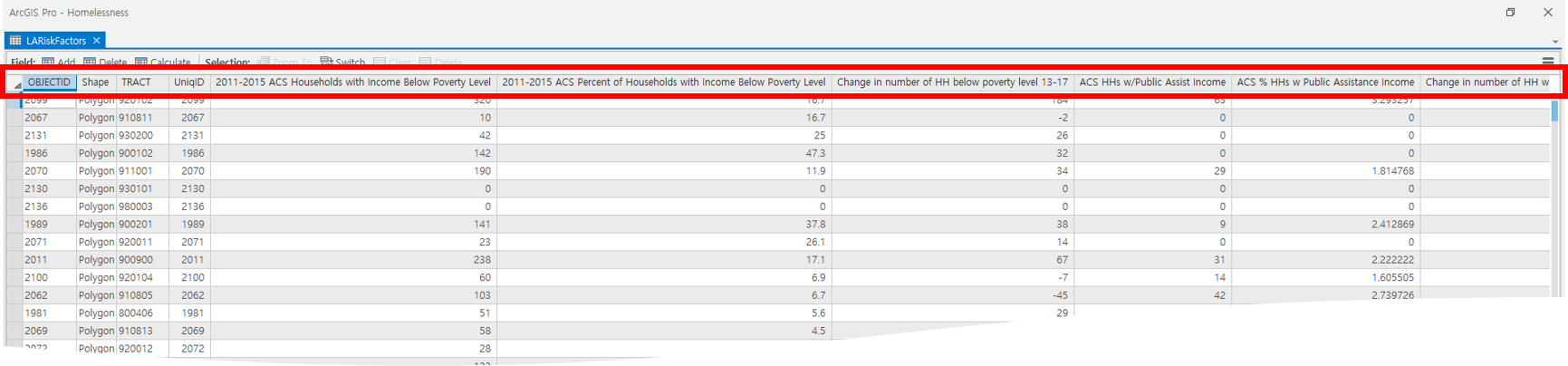
- 평균 이하의 소득을 가진 가구 수/비율
- 평균 이하의 소득이 있는 세대 변화
- 공공 보조가 있는 세대 수 소득/가구의 비율 등
※ 이번 실습에서는 세대 소득이 평균 이하인 데이터를 이용하여 심각성을 조사합니다.
☞ 유사성 검사
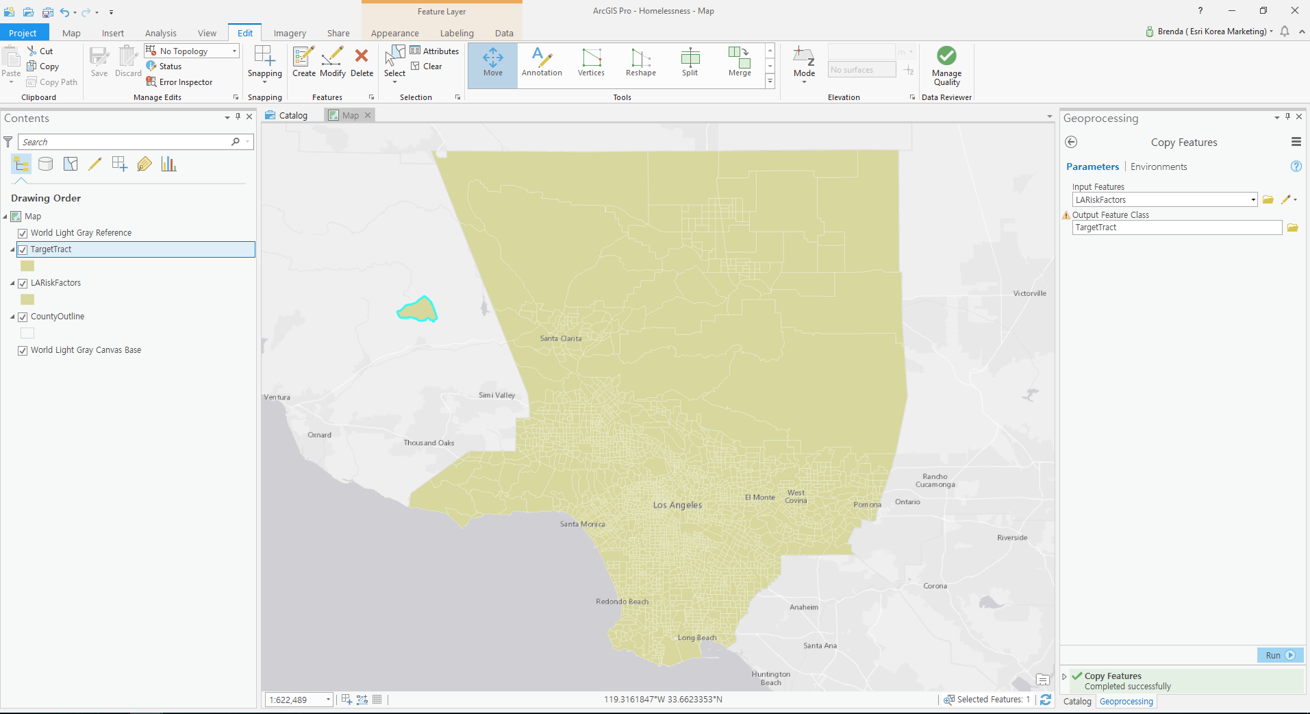
> 유사성 검사 대상 지역 선정 및 피처 복사
-
대상 지역에서 마음에 드는 필지 [선택(Select)]
-
[피처 복사(Copy Feature)]를 사용하여 유사성 검사 대상 지역 생성
– 입력 피처(Target Features): LARiskFactors
– 결과 피처 클래스(Output Feature Class): TargetTract -
LARiskFactors 레이어를 끄고 [편집(Edit)] → [선택(Select)] → ‘TargetTract’에서 대상 피처를 선택 → [이동(Move)] → ‘TargetTract’피처를 연구 영역 밖에 드래그 → [마침(Finish)] → [저장(Save)]
> 대상 필지의 속성 변경
-
‘TargetTract’레이어 및 ‘LASRiskFactor’레이어의 속성 테이블 열기
-
LASRiskFactor’레이어 속성 테이블 → 2011-2015 ACS 세대 평균 이하 소득 수준(2011-2015 ACS Households with Income Below Poverty Level) 필드를 내림차순 → 최댓값 확인
-
‘TargetTract’레이어 속성 테이블 → [편집(Edit)] → 레코드 값 입력: 1809 → [저장(Save)]
( ‘LASRiskFactor’레이어에 있는 최댓값으로 ‘TragetTract’ 레이어의 변수를 설정합니다.)
> 유사성 검사
-
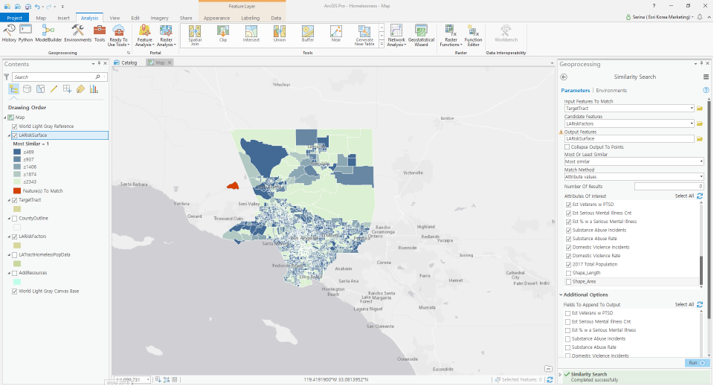
[유사성 검사(Similarity Search)]를 사용하여 유사성 검사 대상 지역 생성
– 매칭할 입력 피처(Input Featrues to Match): TargetTract
– 후보 피처(Candidate Features): LARiskFactros
– 결과 피처(Output Features): LARiskSurface
– 포인트로 결과물 산출(Collapse Output To Points) 체크 안 함
– 유사/반대 여부(Most of Least Similar): 가장 유사(Most Similar)
– 검색 방법(Match Method): 속성 값(Attribute Values)
– 결과 수(Number of Results): 0
(모든 후보 피처의 우선순위를 결과로 산출하려면 매개변수에 0을 입력)
– 관심 지점의 속성(Attributes of Interest): UniqID, Shape_Length, Shape_Area를 제외하고 모두 체크
– 결과에 추가할 필드(Fields to Append to Output): Tract, UniqID 체크
> 산출된 결과 심볼 변경
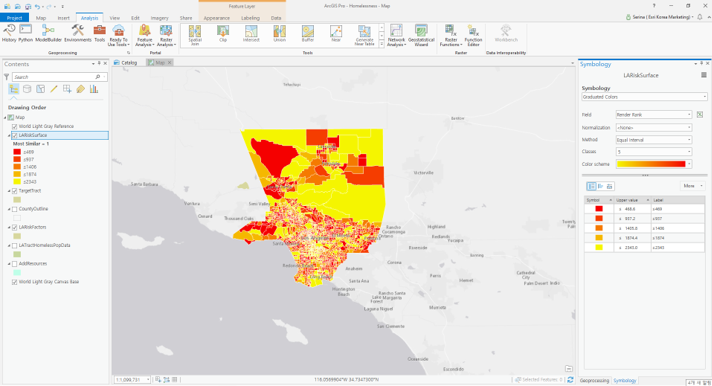
- ‘LARiskSurface’레이어 → 심볼(Symbology) → 색상 변경(붉은색 계열) → 역순(Reverse Order) 클릭
- 산출된 결과는 심각성을 나타내는 것으로 심볼을 붉은색 계열로 바꿔주고, 숫자가 적을수록 유사성이 높다는 것으로 심각성을 의미하기 때문에 역순으로 설정합니다.
☞ 속성 조인 및 필드 값 계산
> 속성 조인
- ‘LARiskFactors’레이어에 ‘LARiskSurface’레이어에 있는 속성을 연결하기 위한 [조인(Join)] 클릭
– 입력 테이블(Input Table): LARiskFactors
– 입력 조인 필드 (Input Join Field): OBJECTID
– 조인 테이블(Join Table): LARiskSurface
– 결과 조인 필드(Output Join Field): CAND_ID
– 조인 필드(Join Fields): Render Rank
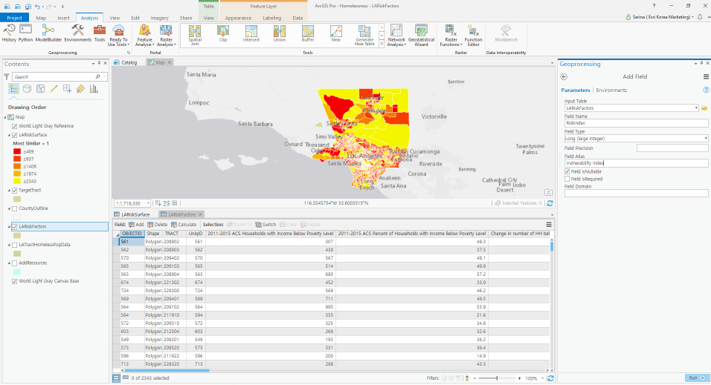
> 필드 생성
- 테이블에 필드 생성을 위한 [필드 추가(Add Field)] 클릭
– 입력 테이블(Input Table): LARiskFactors
– 필드 이름(Field Name): Vulnerability Index
> 필드 값 채우기
- 필드 값 채우기를 위한 [필드 추가(Add Field)] 클릭
– 입력 테이블(Input Table): LARiskFactors
– 필드 이름(Field Name): Vulnerability Index
– 식 유형(Expression Type): Python 3
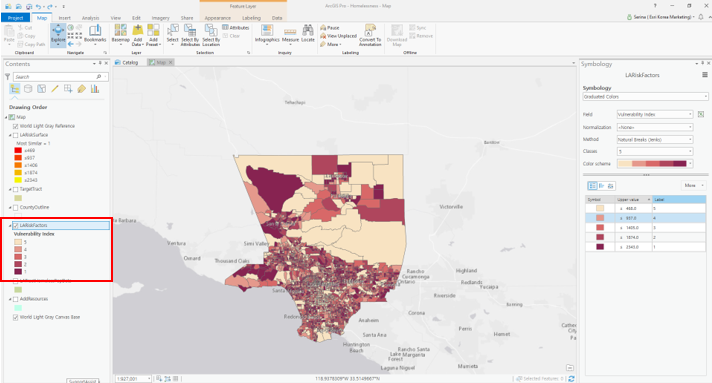
– 식(Expression): 2344 – !LABELRANK!(Render Rank)
- Render Rank ‘2343’ 값이 가장 취약성이 낮은 지역으로 ‘2344’에서 해당 값을 빼주면 취약 지수가 생성됩니다. 취약 지수가 높을수록 노숙자가 많을 가능성이 높음을 의미합니다. 아래 결과는 취약 지수를 5단계로 구분하여 나타냈으며 레벨 5인 지역은 비교적 노숙자가 적을 가능성이 있는 지역이며, 레벨 1인 지역은 노숙자가 많을 가능성이 있는 지역을 나타냅니다.
지금까지 데이터 관계성을 이용한 공간 분석을 알아봤습니다. 데이터의 속성을 이용하여 생성, 계산, 조인을 실행하고, 유사성 검색을 통한 취약 지수를 분석해봤습니다. 방대하게 나열된 테이블 데이터와 달리 지도에 시각화된 데이터는 파악하고자 하는 현상을 한눈에 식별할 수 있는 큰 장점을 갖고 있습니다. 이번 실습에서 취약성을 나타내는 기준을 소득 이하의 빈곤 필드를 이용하여 수행하였지만, 사용자의 판단에 따라 다른 필드를 이용하여 수행할 수도 있답니다.
지금 당장 데이터를 다운받아 실행해보세요! 🙂